
100% Open Source
The full code base is open under the Apache 2.0 license, including pre-trained models and pipelines

Natively scalable
The only NLP library built natively on Apache Spark

Multiple Languages
Full Python, Scala, and Java support
Transformers at Scale
Unlock the power of Large Language Models with Spark NLP 🚀, the only open-source library that delivers cutting-edge transformers for production such as
BERT, CamemBERT, ALBERT, ELECTRA, XLNet, DistilBERT, RoBERTa, DeBERTa,
XLM-RoBERTa, Longformer, ELMO, Universal Sentence Encoder, Facebook BART, Instructor Embeddings, E5 Embeddings, MPNet Embeddings, Google T5, MarianMT, OpenAI GPT2,
Google ViT, ASR Wav2Vec2, OpenAI Whisper and many more not only to Python, and R but also to JVM ecosystem (Java and Scala) at scale by extending Apache Spark natively
The most widely used NLP library in the enterprise
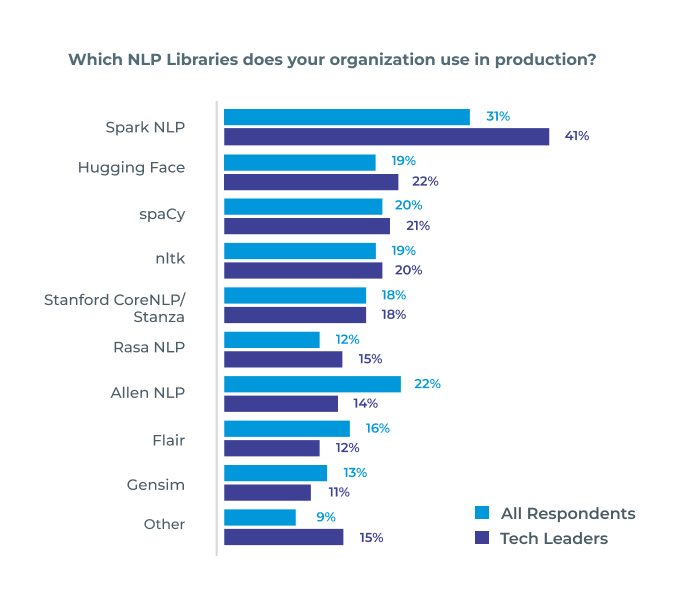
Gradient Flow NLP Survey, 2021.
Right Out of The Box
Spark NLP 🚀 ships with many NLP features, pre-trained models and pipelines
NLP Features
- Tokenization
- Word Segmentation
- Stop Words Removal
- Document & Text Splitter
- Normalizer
- Stemmer
- Lemmatizer
- NGrams
- Regex Matching
- Text Matching
- Chunking
- Date Matcher
- Part-of-speech tagging
- Sentence Detector (DL models)
- Dependency parsing
- SpanBERT Coreference Resolution
- Sentiment Detection (ML models)
- Spell Checker (ML & DL models)
- Doc2Vec Embeddings (Word2Vec)
- Word2Vec Embeddings (Word2Vec)
- Word Embeddings (GloVe & Word2Vec)
- BERT Embeddings
- DistilBERT Embeddings
- CamemBERT Embeddings
- RoBERTa Embeddings
- DeBERTa Embeddings
- XLM-RoBERTa Embeddings
- Longformer Embeddings
- ALBERT Embeddings
- XLNet Embeddings
- ELMO Embeddings
- Universal Sentence Encoder
- Sentence Embeddings
- Chunk Embeddings
- Instructor Embeddings
- E5 Embeddings
- MPNet Embeddings
- OpenAI Embeddings
- Table Question Answering (TAPAS)
- Unsupervised keywords extraction
- Language Detection & Identification (up to 375 languages)
- Multi-class / Multi-label Text Classification (DL model)
- Text Classification (DL model)
- Multi-class Sentiment Analysis (DL model)
- BERT for Token & Sequence Classification
- DistilBERT for Token & Sequence Classification
- CamemBERT for Token Classification
- ALBERT for Token & Sequence Classification
- RoBERTa for Token & Sequence Classification
- DeBERTa for Token & Sequence Classification
- XLM-RoBERTa for Token & Sequence Classification
- XLNet for Token & Sequence Classification
- Longformer for Token & Sequence Classification
- Transformer-based Question Answering
- Named entity recognition (DL model)
- Facebook BART NLG, Translation, and Comprehension
- Zero-Shot NER & Text Classification (ZSL)
- Neural Machine Translation (MarianMT)
- Many-to-Many multilingual translation (Facebook M2M100)
- Text-To-Text Transfer Transformer (Google T5)
- Generative Pre-trained Transformer 2 (OpenAI GPT-2)
- Chat and Conversational LLMs (Facebook Llama-22)
- Vision Transformer (Google ViT) Image Classification
- Microsoft Swin Transformer Image Classification
- Facebook ConvNext Image Classification
- Image to Text Image Captioning
- Zero-Shot Image Classification (OpenAI CLIP)
- Automatic Speech Recognition (OpenAI Whisper, Wav2Vec2 & HuBERT)
- Easy ONNX and TensorFlow integrations
- GPU Support
- Full integration with Spark ML functions
- 24000+ pre-trained models in 200+ languages!
- 6000+ pre-trained pipelines in 200+ languages!
from sparknlp.pretrained import PretrainedPipeline
import sparknlp
# Start Spark Session with Spark NLP 🚀
spark = sparknlp.start()
# Download a pre-trained pipeline
pipeline = PretrainedPipeline('explain_document_dl', lang='en')
# Annotate your testing dataset
text = "The Mona Lisa is a 16th century oil painting created by Leonardo. It's held at the Louvre in Paris."
result = pipeline.annotate(text)
# What's in the pipeline
print(list(result.keys()))
# Output: ['entities', 'stem', 'checked', 'lemma', 'document', 'pos', 'token', 'ner', 'embeddings', 'sentence']
# Check the results
print(result['entities'])
# Output: ['Mona Lisa', 'Leonardo', 'Louvre', 'Paris']Benchmark
Spark NLP 🚀 4.x obtained the best performing academic peer-reviewed results
Training NER
- State-of-the-art Deep Learning algorithms
- Achieve high accuracy within a few minutes
- Achieve high accuracy with a few lines of codes
- Blazing fast training
- Use CPU or GPU
- 700+ Pretrained Embeddings including GloVe, Word2Vec, BERT, DistilBERT, CamemBERT, RoBERTa, DeBERTa, XLM-RoBERTa, Longformer, ELMO, ELECTRA, ALBERT, XLNet, BioBERT, etc.
- Multi-lingual NER models in Arabic, Bengali, Chinese, Danish, Dutch, English, Finnish, French, German, Hebrew, Italian, Japanese, Korean, Norwegian, Persian, Polish, Portuguese, Russian, Spanish, Swedish, Urdu, and many more!
| SYSTEM | YEAR | LANGUAGE | CONLL ‘03 |
|---|---|---|---|
| Spark NLP v4 🚀 | 2022 | Python/Scala/Java/R | 93 (test F1) 96 (dev F1) |
| Spark NLP v3 🚀 | 2021 | Python/Scala/Java/R | 93 (test F1) 95 (dev F1) |
| spaCy v3 | 2021 |
Python | 91.6 |
| Stanza (StanfordNLP) | 2020 |
Python | 92.1 |
| Flair | 2018 | Python | 93.1 |
| CoreNLP | 2015 | Java | 89.6 |
| SYSTEM | YEAR | LANGUAGE | ONTONOTES |
|---|---|---|---|
| Spark NLP v3 🚀 | 2021 | Python/Scala/Java/R | 90.0 (test F1) 92.5 (dev F1) |
| spaCy RoBERTa | 2020 |
Python | 89.8 (dev F1) |
| Stanza (StanfordNLP) | 2020 |
Python | 88.8 (dev F1) |
| Flair | 2018 | Python | 89.7 |
Trusted By












