This section includes benchmarks for different Approach() (training classes), comparing their performance when running in m5.8xlarge CPU vs a Tesla V100 SXM2 GPU, as described in the Machine Specs section below.
Different benchmarks, as well as their takeaways and some conclusions of how to get the best of GPU, are included as well, to guide you in the process of getting the best performance out of Spark NLP on GPU.
Each major release comes with big improvements, so please, make sure you use at least that version to fully levearge Spark NLP capabilities on GPU.
Machine specs
CPU
An AWS m5.8xlarge machine was used for the CPU benchmarking. This machine consists of 32 vCPUs and 128 GB of RAM, as you can check in the official specification webpage available here
GPU
A Tesla V100 SXM2 GPU with 32GB of memory was used to calculate the GPU benchmarking.
Versions
The benchmarking was carried out with the following Spark NLP versions:
Spark version: 3.0.2
Hadoop version: 3.2.0
SparkNLP version: 3.3.4
Spark nodes: 1
Benchmark on classifierDLApproach()
This experiment consisted of training a Deep Learning Binary Classifier (Question vs Statement classes) at sentence-level, using a fully connected CNN and Bert Sentence Embeddings. Only 1 Spark node was usd for the training.
We used the Spark NLP class ClassifierDL and it’s method Approach() as described in the documentation.
The pipeline looks as follows:
Dataset
The size of the dataset was relatively small (200K), consisting of:
Training (rows): 162250
Test (rows): 40301
Training params
Different batch sizes were tested to demonstrate how GPU performance improves with bigger batches compared to CPU, for a constant number of epochs and learning rate.
Epochs: 10
Learning rate: 0.003
Batch sizes: 32, 64, 256, 1024
Results
Even for this average-sized dataset, we can observe that GPU is able to beat the CPU machine by a 76% in both training and inference times.
Training times depending on batch (in minutes)
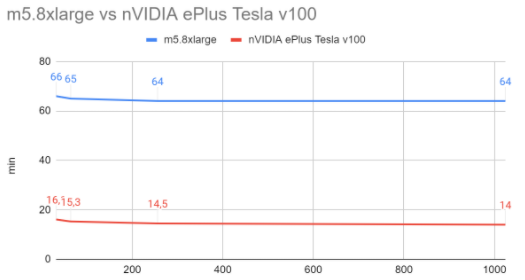
| Batch size | CPU | GPU |
|---|---|---|
| 32 | 66 | 16.1 |
| 64 | 65 | 15.3 |
| 256 | 64 | 14.5 |
| 1024 | 64 | 14 |
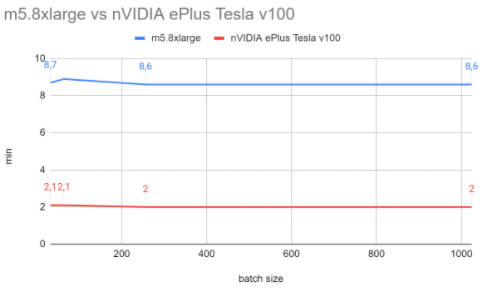
Inference times (in minutes)
The average inference time remained more or less constant regardless the batch size:
CPU: 8.7 min
GPU: 2 min
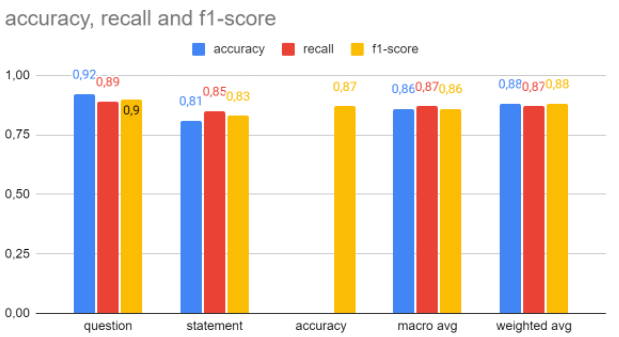
Performance metrics
A weighted F1-score of 0.88 was achieved, with a 0.90 score for question detection and 0.83 for statements.
Benchmark on NerDLApproach()
This experiment consisted of training a Name Entity Recognition model (token-level), using our class NerDLApproach(), using Bert Word Embeddings and a Char-CNN-BiLSTM Neural Network. Only 1 Spark node was used for the training.
We used the Spark NLP class NerDL and it’s method Approach() as described in the documentation.
The pipeline looks as follows:
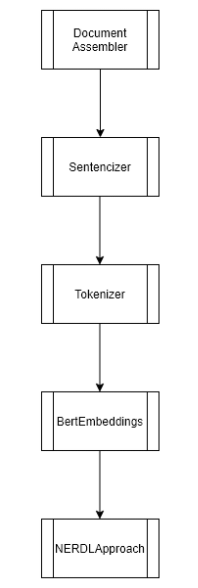
Dataset
The size of the dataset was small (17K), consisting of:
Training (rows): 14041
Test (rows): 3250
Training params
Different batch sizes were tested to demonstrate how GPU performance improves with bigger batches compared to CPU, for a constant number of epochs and learning rate.
Epochs: 10
Learning rate: 0.003
Batch sizes: 32, 64, 256, 512, 1024, 2048
Results
Even for this small dataset, we can observe that GPU is able to beat the CPU machine by a 62% in training time and a 68% in inference times. It’s important to mention that the batch size is very relevant when using GPU, since CPU scales much worse with bigger batch sizes than GPU.
Training times depending on batch (in minutes)
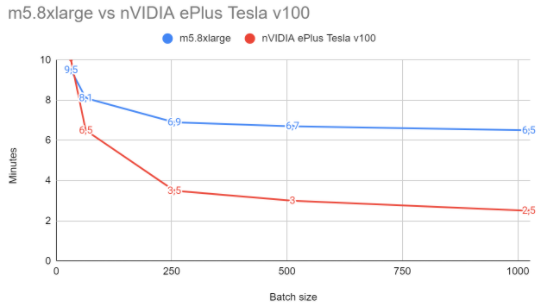
| Batch size | CPU | GPU |
|---|---|---|
| 32 | 9.5 | 10 |
| 64 | 8.1 | 6.5 |
| 256 | 6.9 | 3.5 |
| 512 | 6.7 | 3 |
| 1024 | 6.5 | 2.5 |
| 2048 | 6.5 | 2.5 |
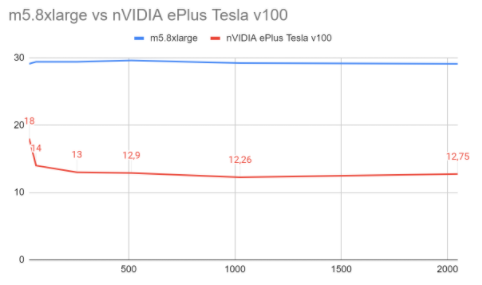
Inference times (in minutes)
Although CPU times in inference remain more or less constant regardless the batch sizes, GPU time experiment good improvements the bigger the batch size is.
CPU times: ~29 min
| Batch size | GPU |
|---|---|
| 32 | 10 |
| 64 | 6.5 |
| 256 | 3.5 |
| 512 | 3 |
| 1024 | 2.5 |
| 2048 | 2.5 |
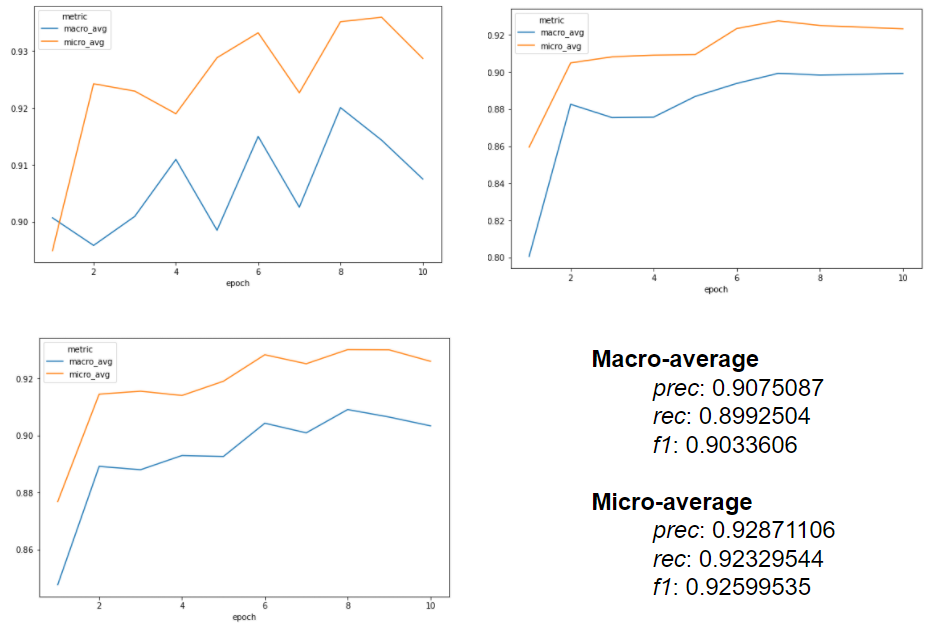
Performance metrics
A macro F1-score of about 0.92 (0.90 in micro) was achieved, with the following charts extracted from the NERDLApproach() logs:
Inference benchmark on BertSentenceEmbeddings()
This experiment consisted of benchmarking the improvement obtained in inference by using GPU on BertSentenceEmbeddings().
We used the Spark NLP class BertSentenceEmbeddings() described in the Transformers documentation.
The pipeline contains only two components and looks as follows:
Dataset
The size of the dataset was bigger than the previous ones, with 417735 rows for inference.
Results
We have observed in previous experiments, using BertSentenceEmbeddings (classifierDL) and also BertEmbeddings (NerDL) how GPU improved both training and inference times. In this case, we observe again big improvements in inference, what is already pointing that one of the main reasons of why GPU improves so much over CPU is the better management of Embeddings (word, sentence level) and bigger batch sizes.
Batch sizes: 32, 64, 256, 1024
Inference times depending on batch (in minutes)
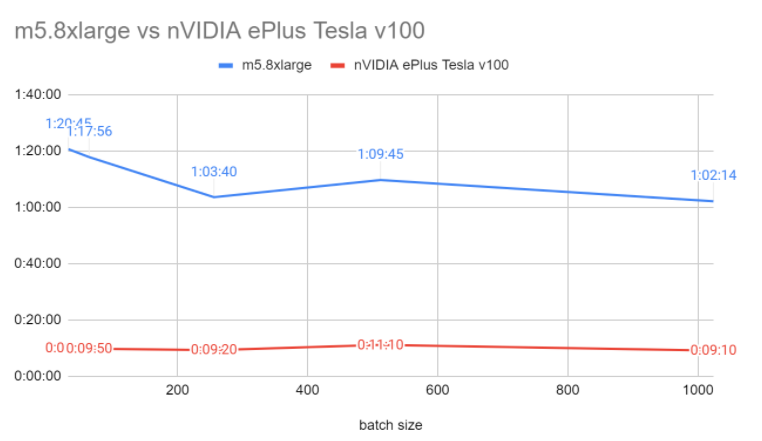
| Batch size | CPU | GPU |
|---|---|---|
| 32 | 80 | 9.9 |
| 64 | 77 | 9.8 |
| 256 | 63 | 9.4 |
| 1024 | 62 | 9.1 |
Takeaways: How to get the best of the GPU
You will experiment big GPU improvements in the following cases:
- Embeddings and Transformers are used in your pipeline. Take into consideration that GPU will performance very well in Embeddings / Transformer components, but other components of your pipeline may not leverage as well GPU capabilities;
- Bigger batch sizes get the best of GPU, while CPU does not scale with bigger batch sizes;
- Bigger dataset sizes get the best of GPU, while may be a bottleneck while running in CPU and lead to performance drops;
MultiGPU training
Right now, we don’t support multigpu training (1 model in different GPUs in parallel), but you can train different models in different GPU.
Where to look for more information about Training
Please, take a look at the Spark NLP and feel free to reach us out in case you want to maximize the performance on your GPU.