Getting started
Spark NLP Display is an open-source python library for visualizing the annotations generated with Spark NLP. It currently offers out-of-the-box suport for the following types of annotations:
- Dependency Parser
- Named Entity Recognition
- Entity Resolution
- Relation Extraction
- Assertion Status
The ability to quickly visualize the entities/relations/assertion statuses, etc. generated using Spark NLP is a very useful feature for speeding up the development process as well as for understanding the obtained results. Getting all of this in a one liner is extremelly convenient especially when running Jupyter notebooks which offers full support for html visualizations.
The visualisation classes work with the outputs returned by both Pipeline.transform() function and LightPipeline.fullAnnotate().
Install Spark NLP Display
You can install the Spark NLP Display library via pip by using:
pip install spark-nlp-display
A complete guideline on how to use the Spark NLP Display library is available here.
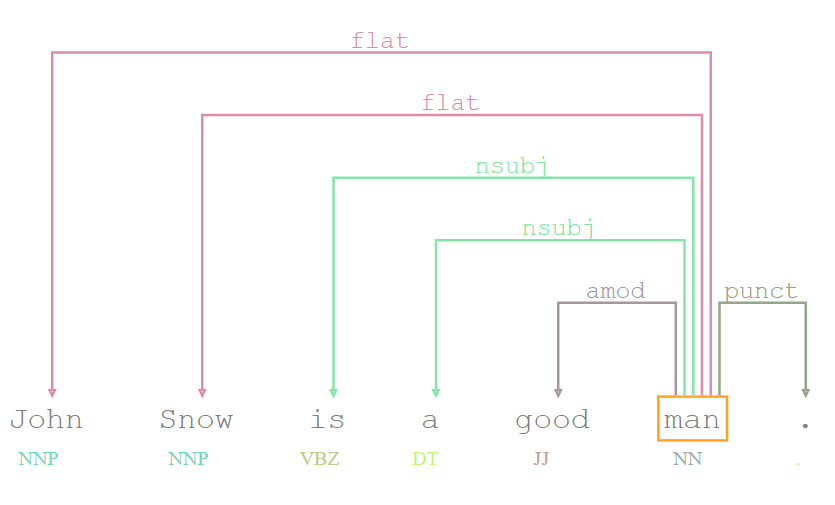
Visualize a dependency tree
For visualizing a dependency trees generated with DependencyParserApproach you can use the following code.
from sparknlp_display import DependencyParserVisualizer
dependency_vis = DependencyParserVisualizer()
dependency_vis.display(pipeline_result[0], #should be the results of a single example, not the complete dataframe.
pos_col = 'pos', #specify the pos column
dependency_col = 'dependency', #specify the dependency column
dependency_type_col = 'dependency_type' #specify the dependency type column
)
The following image gives an example of html output that is obtained for a test sentence:
Visualize extracted named entities
The NerVisualizer highlights the named entities that are identified by Spark NLP and also displays their labels as decorations on top of the analyzed text. The colors assigned to the predicted labels can be configured to fit the particular needs of the application.
from sparknlp_display import NerVisualizer
ner_vis = NerVisualizer()
ner_vis.display(pipeline_result[0], #should be the results of a single example, not the complete dataframe
label_col='entities', #specify the entity column
document_col='document' #specify the document column (default: 'document')
labels=['PER'] #only allow these labels to be displayed. (default: [] - all labels will be displayed)
)
## To set custom label colors:
ner_vis.set_label_colors({'LOC':'#800080', 'PER':'#77b5fe'}) #set label colors by specifying hex codes
The following image gives an example of html output that is obtained for a couple of test sentences:

Visualize relations
The RelationExtractionVisualizer can be used to visualize the relations predicted by Spark NLP. The two entities involved in a relation will be highlighted and their label will be displayed. Also a directed and labeled arc(line) will be used to connect the two entities.
from sparknlp_display import RelationExtractionVisualizer
re_vis = RelationExtractionVisualizer()
re_vis.display(pipeline_result[0], #should be the results of a single example, not the complete dataframe
relation_col = 'relations', #specify relations column
document_col = 'document', #specify document column
show_relations=True #display relation names on arrows (default: True)
)
The following image gives an example of html output that is obtained for a couple of test sentences:

Visualize assertion status
The AssertionVisualizer is a special type of NerVisualizer that also displays on top of the labeled entities the assertion status that was infered by a Spark NLP model.
from sparknlp_display import AssertionVisualizer
assertion_vis = AssertionVisualizer()
assertion_vis.display(pipeline_result[0],
label_col = 'entities', #specify the ner result column
assertion_col = 'assertion' #specify assertion column
document_col = 'document' #specify the document column (default: 'document')
)
## To set custom label colors:
assertion_vis.set_label_colors({'TREATMENT':'#008080', 'problem':'#800080'}) #set label colors by specifying hex codes
The following image gives an example of html output that is obtained for a couple of test sentences:

Visualize entity resolution
Entity resolution refers to the normalization of named entities predicted by Spark NLP with respect to standard terminologies such as ICD-10, SNOMED, RxNorm etc. You can read more about the available entity resolvers here.
The EntityResolverVisualizer will automatically display on top of the NER label the standard code (ICD10 CM, PCS, ICDO; CPT) that corresponds to that entity as well as the short description of the code. If no resolution code could be identified a regular NER-type of visualization will be displayed.
from sparknlp_display import EntityResolverVisualizer
er_vis = EntityResolverVisualizer()
er_vis.display(pipeline_result[0], #should be the results of a single example, not the complete dataframe
label_col='entities', #specify the ner result column
resolution_col = 'resolution'
document_col='document' #specify the document column (default: 'document')
)
## To set custom label colors:
er_vis.set_label_colors({'TREATMENT':'#800080', 'PROBLEM':'#77b5fe'}) #set label colors by specifying hex codes
The following image gives an example of html output that is obtained for a couple of test sentences:
